Sometime back, I mentioned that I tried to load up our taxonomy (with about 1 million medical concepts), into TGNI's Lucene and Neo4J datastores, and the process took 3 weeks to complete (on my 2 CPU desktop at work, as a single threaded process). I've been meaning to see if I could speed it up, but the data was adequate for most of the experiments I was doing, so I did not have enough incentive. Until about 4 weeks ago, when I discovered that I had inadverdently pulled in retired and experimental concepts and that they were interfering with the quality of my output.
My initial plan was to convert the loading process into a Map-Reduce job with Hadoop, but I would have to server-ize Lucene and Neo4j (ie, using SOLR and Neo4j's REST API), and the prospect of having to start up 3 servers to test the application seemed a bit daunting, so I scrapped that idea in favor of just multi-threading the loading application. Although, in retrospect, that would have worked equally well (in terms of effort involved to implement) and would have been more scalable (in terms of the hardware requirements - its far easier to get a bank of low-powered servers than it is to get a single high-powered server).
In this post, I describe the somewhat convoluted process that led to a successful multi-threaded loader implementation, hoping that somewhere in this, there are lessons for people (like myself and possibly a vast majority of Java programmers) to whom writing non-trivial multithreaded apps is like buying a car, ie, something you have to do only once every say 5-7 years.
To provide some context, here is what the flow in my original (single threaded) loader looked like. The code would loop through a bunch of tables in an Oracle database and build concept objects out of it, then send the object to a node service, which consisted of a graph service and an index service. The concept would be added to the Neo4j graph database (and get a node ID in the process), then it would be sent to the index service, which would pass it through the UIMA/Lucene analyzer chain to create an entry (heavily augmented with attributes) in the Lucene index for each name (primary, qualified, synonyms) associated witht he concept.
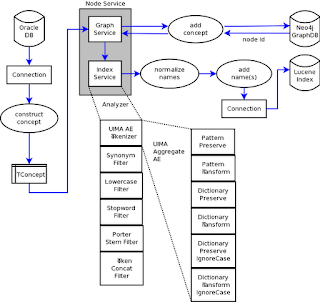
My first implementation was to build a list of OIDs from the Oracle database, then spawn a fixed size thread pool using Java's ExecutorService. Each thread would then build a TConcept object, write to Neo4j, normalize the names and add them (as distinct entities) to the MySQL database. This would run through about 3,000 concepts before hanging. Thinking that perhaps it was something to do with the way I had integrated UIMA with Lucene analyzers, I broke them apart so the UIMA Analysis Engine (AE) would annotate each input name, then break them apart into (potentially) multiple strings, then feed them in, one by one, into the Lucene analyzer chain consisting of streaming Lucene only components (keyword attribute aware LowerCaseFilter, StopFilter and PorterStemFilter).
While I was doing this, I decided to switch out Lucene and use MySQL instead. I was pre-normalizing the names anyway, and I needed to match normalized versions of my input against normalized versions of the concept names. Using Lucene wasn't buying me anything - it was actually hurting because it would match partial strings, and I was having to write code to prevent that.
However, the pipeline would still hang at around the same point. I remembered that I had used Jetlang some time back, and decided to see if modeling it as a Jetlang actor would help. This version ran through about 70,000 concepts before it hung. While I was running this version, I noticed that the CPUs ran a lot cooler (using top and looking at the user CPU consumed) with the Jetlang version compared to my original multithreaded version.
At that point I realized that each of my threads in my original version was creating its own version of the UIMA AE, Lucene Analyzer and database Connection objects for each concept. Since Jetlang uses the Actor model, its threads were basically mini-servers that looped in a read-execute loop.
In an attempt to keep the code mostly intact (I was trying to reuse code as far as possible), I factored out these resources into pools using Commons-Pool and replaced the constructor (and destructor) calls with calls to pool.borrowObject() and pool.returnObject(). This helped, in the sense that I noticed less CPU utilization, but the job would just mysteriously block at around the same point, ie, no movement in the logs, top showing no activity except in one or two CPUs.
Digging deeper, I found that chemical names were being caught by my semantic hyphen transformation pattern (meant to expand hyphenated words into two word and single word tokens), and were generating thousands of synonyms for them.
At the same time, I realized that I could dispense with the pools altogether by modeling my threads as mini-servers (with a for(;;) loop breakable with a poison pill message) and giving each thread its own copy of an UIMA AE, Analyzer, Oracle and MySQL Connection objects. Neo4j allows only a single connection to the database, but is thread-safe, so I wrapped the connection in a singleton and gave each mini-server a reference to the singleton.
For chemical names, I put in an additional AE and changed the flow so if a string (or part of it) was already annotated, a downstream AE will not attempt to annotate it. However, just in case there were other wierd patterns lurking in the input, I wanted to be able to terminate the normalization process (and not process the concept) if it took "too long" to execute, so it did not hold up other concepts that could be processed.
With all these requirements, I ended up modeling the job in three levels - the manager which instantiates everything and creates a queue of input ids to process, a pool of worker threads which are mini-servers and which have their own instances of expensive resources, and normalization tasks, which are instantiated as callable futures from within the worker threads, and which timeout after a configurable amount of time (default 1s), and cause the UIMA CAS (an expensive resource that should be destroyed according to the UIMA docs) to be released and the AE rebuilt with a new CAS when that happens.
Here's the code (with the application specific stuff elided to keep it short, since it adds nothing to the discussion).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440 | // Source: src/main/java/com/mycompany/tgni/loader/ConceptLoadManager.java
package com.mycompany.tgni.loader;
import java.io.File;
import java.io.Reader;
import java.math.BigDecimal;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.Callable;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
import java.util.concurrent.atomic.AtomicInteger;
import opennlp.tools.util.Pair;
import org.apache.commons.collections15.CollectionUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.LowerCaseFilter;
import org.apache.lucene.analysis.en.PorterStemFilter;
import org.apache.lucene.analysis.standard.StandardTokenizer;
import org.apache.lucene.util.Version;
import org.apache.uima.analysis_engine.AnalysisEngine;
import org.apache.uima.jcas.JCas;
import org.neo4j.graphdb.GraphDatabaseService;
import org.neo4j.graphdb.Node;
import org.neo4j.graphdb.Transaction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
//import org.springframework.util.StopWatch;
import com.mycompany.tgni.beans.TConcept;
import com.mycompany.tgni.lucene.StopFilter;
import com.mycompany.tgni.neo4j.GraphInstance;
import com.mycompany.tgni.neo4j.JsonUtils;
import com.mycompany.tgni.neo4j.NameNormalizer;
import com.mycompany.tgni.uima.utils.UimaUtils;
public class ConceptLoadManager {
private final Logger logger = LoggerFactory.getLogger(getClass());
private static final int NUM_WORKERS =
Math.round(1.4F * Runtime.getRuntime().availableProcessors());
private static final long TASK_TIMEOUT_MILLIS = 1000L;
private static final CountDownLatch LATCH = new CountDownLatch(NUM_WORKERS);
private static final BlockingQueue<Integer> QUEUE =
new LinkedBlockingQueue<Integer>();
// oracle queries
private static final String LIST_OIDS_SQL = "...";
private static final String GET_HEAD_SQL = "...";
private static final String GET_PNAMES_SQL = "...";
private static final String GET_SYNS_SQL = "...";
private static final String GET_STY_SQL = "...";
// mysql queries
private static final String ADD_NAME_SQL =
"insert into oid_name (" +
"oid, name, pri) " +
"values (?,?,?)";
private static final String ADD_NID_SQL =
"insert into oid_nid (oid, nid) values (?, ?)";
public static void main(String[] args) throws Exception {
// extract parameters from command line
if (args.length != 5) {
System.out.println("Usage: ConceptLoadManager " +
"/path/to/graph/dir /path/to/mysql-properties " +
"/path/to/stopwords/file /path/to/ae/descriptor " +
"/path/to/oracle-properties");
System.exit(-1);
}
// Initialize manager
ConceptLoadManager manager = new ConceptLoadManager();
final GraphInstance neo4jConn = new GraphInstance(args[0]);
final String mysqlProps = args[1];
final Set<?> stopwords = StopFilter.makeStopSet(
Version.LUCENE_40, new File(args[2]));
final String aeDescriptor = args[3];
final String oraProps = args[4];
// seed input queue
manager.seed(oraProps);
// add poison pills
for (int i = 0; i < NUM_WORKERS; i++) {
try {
QUEUE.put(-1);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
// set up worker threads
ExecutorService workerPool = Executors.newFixedThreadPool(NUM_WORKERS);
for (int i = 0; i < NUM_WORKERS; i++) {
ConceptLoadWorker worker =
new ConceptLoadManager().new ConceptLoadWorker(
i, mysqlProps, stopwords, aeDescriptor,
oraProps, neo4jConn);
workerPool.execute(worker);
}
// wait for all tasks to process, then shutdown
workerPool.shutdown();
try {
LATCH.await();
} catch (InterruptedException e) { /* NOOP */ }
neo4jConn.destroy();
workerPool.awaitTermination(1000L, TimeUnit.MILLISECONDS);
}
private void seed(String oraProps) {
List<Integer> oids = new ArrayList<Integer>();
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
conn = DbConnectionUtils.getConnection(oraProps);
ps = conn.prepareStatement(LIST_OIDS_SQL);
rs = ps.executeQuery();
while (rs.next()) {
QUEUE.put(rs.getInt(1));
}
} catch (Exception e) {
logger.warn("Can't generate OIDs to process", e);
} finally {
DbConnectionUtils.closeResultSet(rs);
DbConnectionUtils.closePreparedStatement(ps);
DbConnectionUtils.closeConnection(conn);
}
}
/////////////// Worker Class ///////////////////
private class ConceptLoadWorker implements Runnable {
private int workerId;
private AtomicInteger count;
private int totalTasks;
private Set<?> stopwords;
private String mysqlProps;
private String aeDescriptor;
private String oraProps;
private GraphInstance neo4jConn;
private Connection mysqlConn;
private PreparedStatement psAddNames, psAddNid;
private Connection oraConn;
private PreparedStatement psGetHead, psGetNames, psGetSyns, psGetSty;
private AnalysisEngine ae;
private JCas jcas;
private Analyzer analyzer;
public ConceptLoadWorker(int workerId, String mysqlProps,
Set<?> stopwords, String aeDescriptor,
String oraProps, GraphInstance neo4jConn) {
this.workerId = workerId;
this.count = new AtomicInteger(0);
this.totalTasks = QUEUE.size();
this.mysqlProps = mysqlProps;
this.stopwords = stopwords;
this.aeDescriptor = aeDescriptor;
this.oraProps = oraProps;
this.neo4jConn = neo4jConn;
}
@Override
public void run() {
try {
initWorker();
ExecutorService taskExec = Executors.newSingleThreadExecutor();
for (;;) {
Integer oid = QUEUE.take();
if (oid < 0) {
break;
}
int curr = count.incrementAndGet();
// load the concept by OID from oracle
TConcept concept = null;
try {
concept = loadConcept(oid);
} catch (SQLException e) {
logger.warn("Exception retrieving concet (OID:" +
oid + ")", e);
continue;
}
// normalize names using UIMA/Lucene chains. This is
// a slow process so we want to time this out if it
// takes too long. In that case, the node/oid mapping
// will not be written out into Neo4J.
NameNormalizer normalizer = new NameNormalizer(ae, analyzer, jcas);
NameNormalizerTask task = new NameNormalizerTask(
concept, normalizer);
Future<List<Pair<String,Boolean>>> futureResult =
taskExec.submit(task);
List<Pair<String,Boolean>> result = null;
try {
result = futureResult.get(
TASK_TIMEOUT_MILLIS, TimeUnit.MILLISECONDS);
} catch (ExecutionException e) {
logger.warn("Task (OID:" + oid + ") skipped", e);
reinitWorker();
continue;
} catch (TimeoutException e) {
futureResult.cancel(true);
logger.warn("Task (OID:" + oid + ") timed out", e);
reinitWorker();
continue;
}
try {
// add the OID-Name mappings to MySQL
addNames(oid, result);
// add the OID-NID mapping to Neo4j
writeNodeConceptMapping(concept);
} catch (Exception e) {
logger.warn("Exception persisting concept (OID:" + oid +
")", e);
continue;
}
// report on progress
if (curr % 100 == 0) {
logger.info("Worker " + workerId + " processed (" + curr +
"/" + totalTasks + ") OIDs");
}
}
taskExec.shutdownNow();
} catch (InterruptedException e) {
logger.error("Worker:" + workerId + " Interrupted", e);
} catch (Exception e) {
logger.error("Worker:" + workerId + " threw exception", e);
} finally {
destroyWorker();
LATCH.countDown();
}
}
private TConcept loadConcept(Integer oid) throws SQLException {
TConcept concept = new TConcept();
// bunch of SQLs run against Oracle database to populate
// the concept
...
return concept;
}
private void addNames(Integer oid,
List<Pair<String, Boolean>> names)
throws SQLException {
if (names == null) return;
try {
psAddNames.clearBatch();
for (Pair<String,Boolean> name : names) {
if (StringUtils.length(StringUtils.trim(name.a)) > 255) {
continue;
}
psAddNames.setInt(1, oid);
psAddNames.setString(2, name.a);
psAddNames.setString(3, name.b ? "T" : "F");
psAddNames.addBatch();
}
psAddNames.executeBatch();
mysqlConn.commit();
} catch (SQLException e) {
mysqlConn.rollback();
throw e;
}
}
private void writeNodeConceptMapping(TConcept concept)
throws Exception {
logger.info("Writing concept (OID=" + concept.getOid() + ")");
GraphDatabaseService graphService = neo4jConn.getInstance();
Transaction tx = graphService.beginTx();
try {
// update neo4j
Node node = graphService.createNode();
concept.setNid(node.getId());
node.setProperty("oid", concept.getOid());
node.setProperty("pname", concept.getPname());
node.setProperty("qname", concept.getQname());
node.setProperty("synonyms",
JsonUtils.listToString(concept.getSynonyms()));
node.setProperty("stycodes",
JsonUtils.mapToString(concept.getStycodes()));
node.setProperty("stygrp", StringUtils.isEmpty(
concept.getStygrp()) ? "UNKNOWN" : concept.getStygrp());
node.setProperty("mrank", concept.getMrank());
node.setProperty("arank", concept.getArank());
node.setProperty("tid", concept.getTid());
// update mysql
psAddNid.setInt(1, concept.getOid());
psAddNid.setLong(2, concept.getNid());
psAddNid.executeUpdate();
mysqlConn.commit();
tx.success();
} catch (Exception e) {
mysqlConn.rollback();
tx.failure();
logger.info("Exception writing mapping (OID=" +
concept.getOid() + ")");
throw e;
} finally {
tx.finish();
}
}
private void initWorker() throws Exception {
logger.info("Worker:" + workerId + " init");
// mysql
this.mysqlConn = DbConnectionUtils.getConnection(mysqlProps);
this.mysqlConn.setAutoCommit(false);
this.psAddNames = mysqlConn.prepareStatement(ADD_NAME_SQL);
this.psAddNid = mysqlConn.prepareStatement(ADD_NID_SQL);
// oracle
this.oraConn = DbConnectionUtils.getConnection(oraProps);
this.psGetHead = oraConn.prepareStatement(GET_HEAD_SQL);
this.psGetNames = oraConn.prepareStatement(GET_PNAMES_SQL);
this.psGetSyns = oraConn.prepareStatement(GET_SYNS_SQL);
this.psGetSty = oraConn.prepareStatement(GET_STY_SQL);
// uima/lucene
this.ae = UimaUtils.getAE(aeDescriptor, null);
this.analyzer = getAnalyzer(stopwords);
this.jcas = ae.newJCas();
}
private void destroyWorker() {
// mysql
DbConnectionUtils.closePreparedStatement(psAddNames);
DbConnectionUtils.closePreparedStatement(psAddNid);
DbConnectionUtils.closeConnection(this.mysqlConn);
// oracle
DbConnectionUtils.closePreparedStatement(psGetHead);
DbConnectionUtils.closePreparedStatement(psGetNames);
DbConnectionUtils.closePreparedStatement(psGetSyns);
DbConnectionUtils.closePreparedStatement(psGetSty);
DbConnectionUtils.closeConnection(this.oraConn);
// uima/lucene
this.ae.destroy();
this.analyzer.close();
this.jcas.release();
this.jcas.reset();
}
private void reinitWorker() throws Exception {
this.ae.destroy();
this.analyzer.close();
this.jcas.release();
this.jcas.reset();
this.ae = UimaUtils.getAE(aeDescriptor, null);
this.analyzer = getAnalyzer(stopwords);
this.jcas = ae.newJCas();
}
private Analyzer getAnalyzer(final Set<?> stopwords) {
return new Analyzer() {
@Override
public TokenStream tokenStream(String fieldName, Reader reader) {
TokenStream input = new StandardTokenizer(Version.LUCENE_40, reader);
input = new LowerCaseFilter(Version.LUCENE_40, input);
input = new StopFilter(Version.LUCENE_40, input, stopwords);;
input = new PorterStemFilter(input);
return input;
}
};
}
}
///////////////// Task class ////////////////
private class NameNormalizerTask implements
Callable<List<Pair<String,Boolean>>> {
private TConcept concept;
private NameNormalizer normalizer;
public NameNormalizerTask(TConcept concept, NameNormalizer normalizer) {
this.concept = concept;
this.normalizer = normalizer;
}
@Override
public List<Pair<String,Boolean>> call() throws Exception {
logger.info("Executing task (OID:" + concept.getOid() + ")");
Set<String> uniques = new HashSet<String>();
Set<String> normalizedUniques = new HashSet<String>();
List<Pair<String,Boolean>> results =
new ArrayList<Pair<String,Boolean>>();
String pname = concept.getPname();
if (StringUtils.isNotEmpty(pname) &&
(! uniques.contains(pname))) {
List<String> normalized = normalizer.normalize(pname);
uniques.add(pname);
normalizedUniques.addAll(normalized);
}
String qname = concept.getQname();
if (StringUtils.isNotEmpty(qname) &&
(! uniques.contains(qname))) {
List<String> normalized = normalizer.normalize(qname);
uniques.add(qname);
normalizedUniques.addAll(normalized);
}
for (String normalizedUnique : normalizedUniques) {
results.add(new Pair<String,Boolean>(normalizedUnique, true));
}
Set<String> normalizedUniqueSyns = new HashSet<String>();
normalizedUniqueSyns.addAll(normalizedUniques);
List<String> syns = concept.getSynonyms();
for (String syn : syns) {
if (StringUtils.isNotEmpty(syn) &&
(! uniques.contains(syn))) {
List<String> normalizedSyn = normalizer.normalize(syn);
uniques.add(syn);
normalizedUniqueSyns.addAll(normalizedSyn);
}
}
Collection<String> normalizedSyns = CollectionUtils.subtract(
normalizedUniques, normalizedUniqueSyns);
for (String normalizedSyn : normalizedSyns) {
results.add(new Pair<String,Boolean>(normalizedSyn, false));
}
return results;
}
}
}
|
Since the worker threads were doing a combination of IO (reading from the Oracle database and writing to MySQL and Neo4j) and CPU bound work (normalizing with the UIMA AE and Lucene Analyzers), I ran some timings on a small sample of 1000 concepts and found that it spent approximately 30% of its time doing IO. So based on the formula in Java Concurrency in Practice book:
| num_threads = num_cpus * target_cpu_utilization * (1 + wait/compute)
|
I set the number of worker threads to 22 on my 16 CPU machine. During the run, I noticed that the load average was between 3-4 (which is quite low for a 16 CPU box) and the user CPU utilization percentages hovered in the 2-3% mark on most but 2-3 CPUs, which showed around 40-50% utilization. So there is probably still some room for increasing the number of worker threads. Here is a screenshot of top while the program is running.
With 22 threads, the job finished in a very acceptable time of about 1.5 hours, with 88 concepts timing out. I plan to look at those concepts to see if I can uncover patterns that would lead to the creation of some more pre-emptive AEs in the future.
Meanwhile, I hope I'll remember this stuff the next time I need to build one of these things :-). Its almost Christmas, so for those of you who celebrate it, heres wishing you a very Merry Christmas!
















